Hello all, I have a slight problem in that I need to be able to split a PDF using the indexes provided by SOLindexer (
http://stackoverflow.com/questions/11477272/getting-dictionary-of-values-from-pdfs-internals-using-itextsharp-and-pdfsharp). I have to be able to get the start and end pages of the bookmark so that I can split the PDF. I have been able to drill down using this code:
Code:
var dict = inputDocument.Info.Elements.GetDictionary("/SSEDictionary");
var newdict = dict.Elements.GetDictionary("/Document_MemberStatements");
But I haven't been able to get to the data contained within /Document_MemberStatements. I am able to open the -DATA- file in notepad, and everything I need (account names/numbers) appear to be in there, but they are formatted weird, and I don't know how to apply a filter to them. Please see the attached images for what I'm talking about.
Attachment:
File comment: The structure.
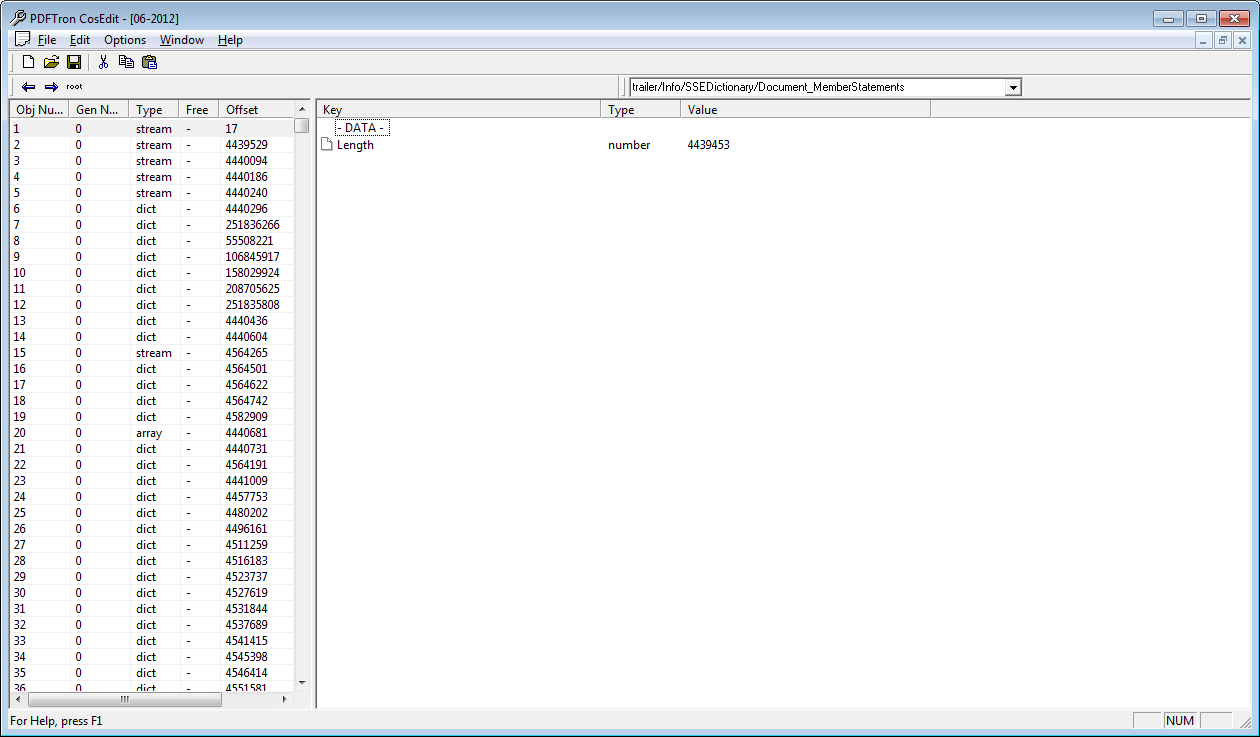 COSEdit.png [ 50.44 KiB | Viewed 3603 times ]
COSEdit.png [ 50.44 KiB | Viewed 3603 times ]
Attachment:
File comment: The data that I think I want.
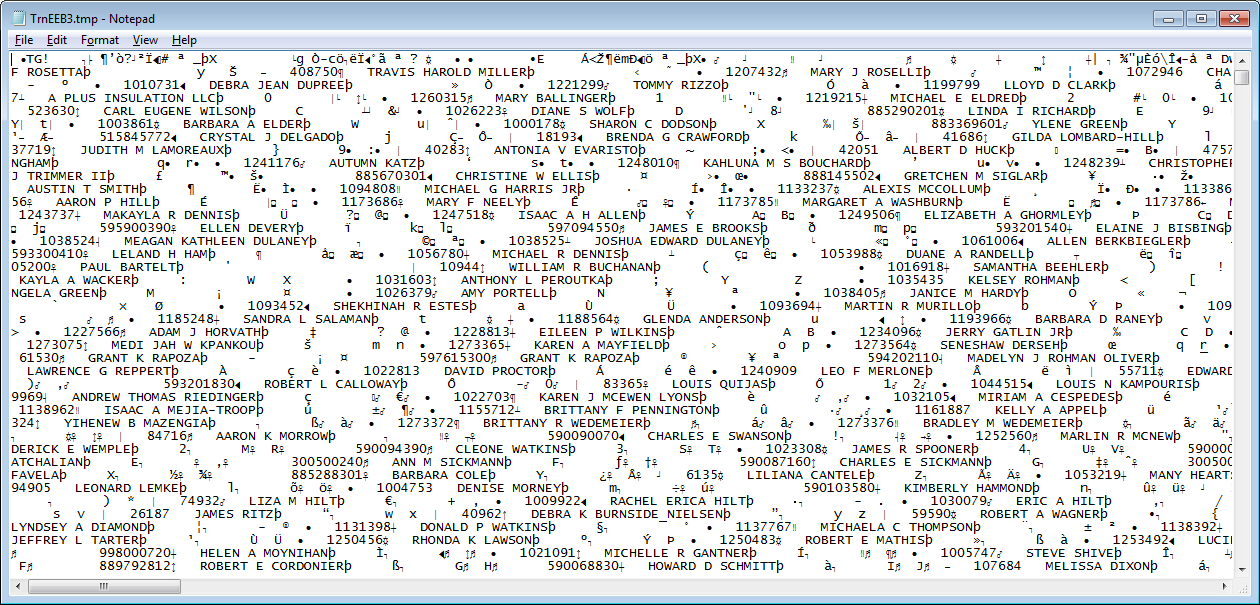 Data.png [ 110.22 KiB | Viewed 3603 times ]
Data.png [ 110.22 KiB | Viewed 3603 times ]

